In this article, we will see how we can read and display the content of a blob field. We will access the content of a clinical note containing a short text in a RTF format:

The problem: blob content is compressed #
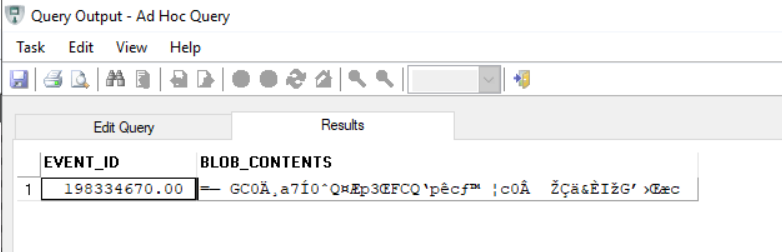
You might have tried to read the blob content with a statement like this:
SELECT
c.event_id
, cb.blob_contents
FROM
ce_blob cb
, clinical_event c
WHERE c.event_id = 198334670.00
AND cb.event_id = c.event_id
You would see something like this:
The solution: Uncompressing blob content #
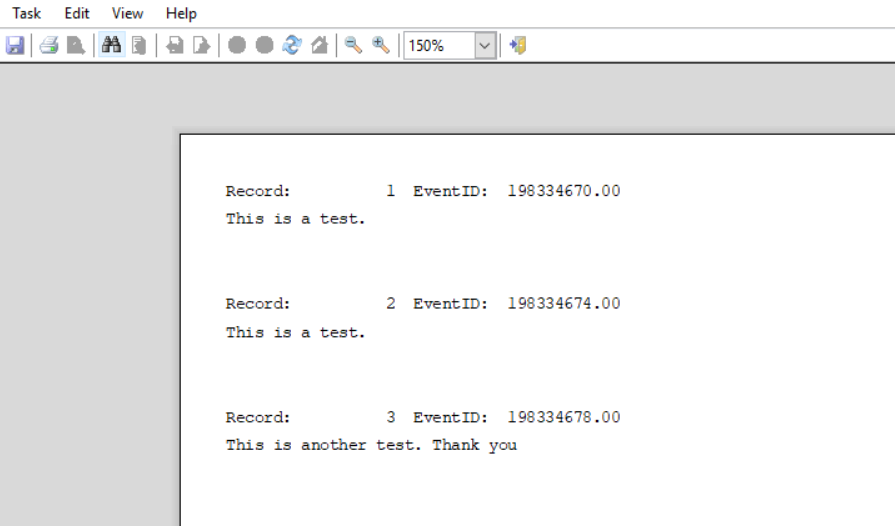
Attached to this article, you will find a CCL program that reads and uncompresses the content of clinical notes. The program from this example reads all notes created on and after the 15th June 2024. For every note, it displays a title in one line and the content bellow the title line (see bellow).
By default, the program is set to strip away the RTF tags so that only the plan text is displayed. However, you can choose to keep the RTF tags. To control this preference, you must comment one of the following lines in the program:
[...]
;--CHOOSE ONE OF THE FOLLOWING STATEMENTS:
col 0 call ccl_text_wrap(col, 100, blobnortf) ;--Remove rtf
;--col 0 call ccl_text_wrap(col, 1000, blobout) ;--Keep rtf
[...]
If we run the program with output to MINE, we will the content of the note like this:
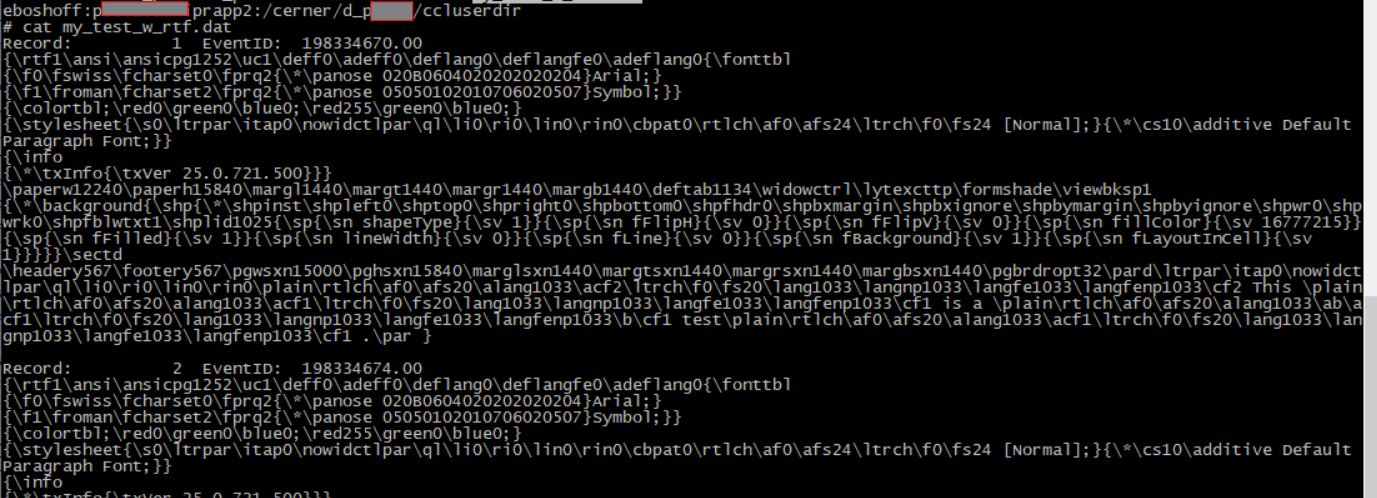
If we choose to keep the rtf tags, we will see the following output:

You could also save the output to a file on the back-end. Without the RTF tags, we would see:

We would see something like this with the RTF tags:
HTML and Image content #
The program attached reads and uncompresses the content as it is stored in the blog field. At most, it allows the option to strip off the RTF tags. However, it does not convert HTML content into plain text. It also does not strip out any image content. This means you would still see content like this:
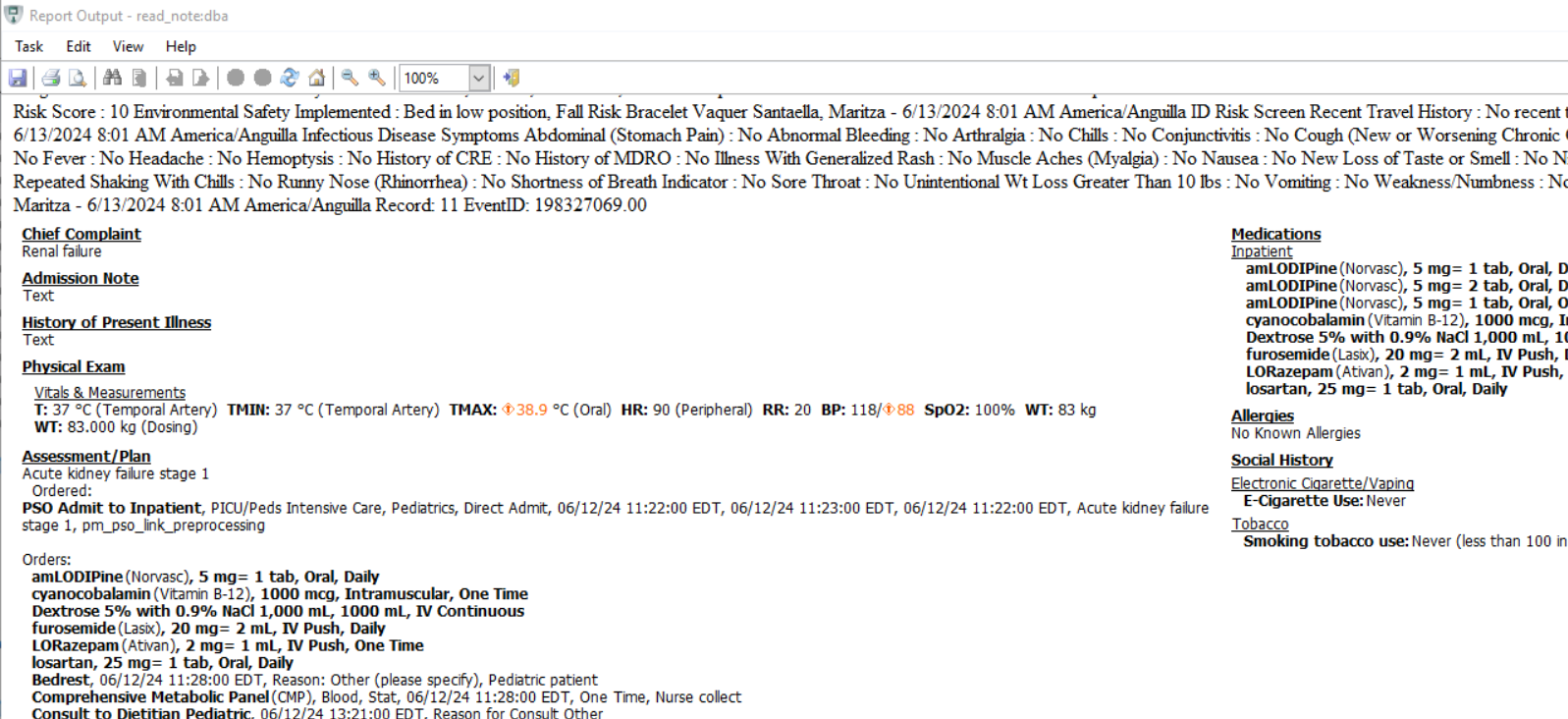
When looking at the raw uncompressed data, you would still see the html tags:
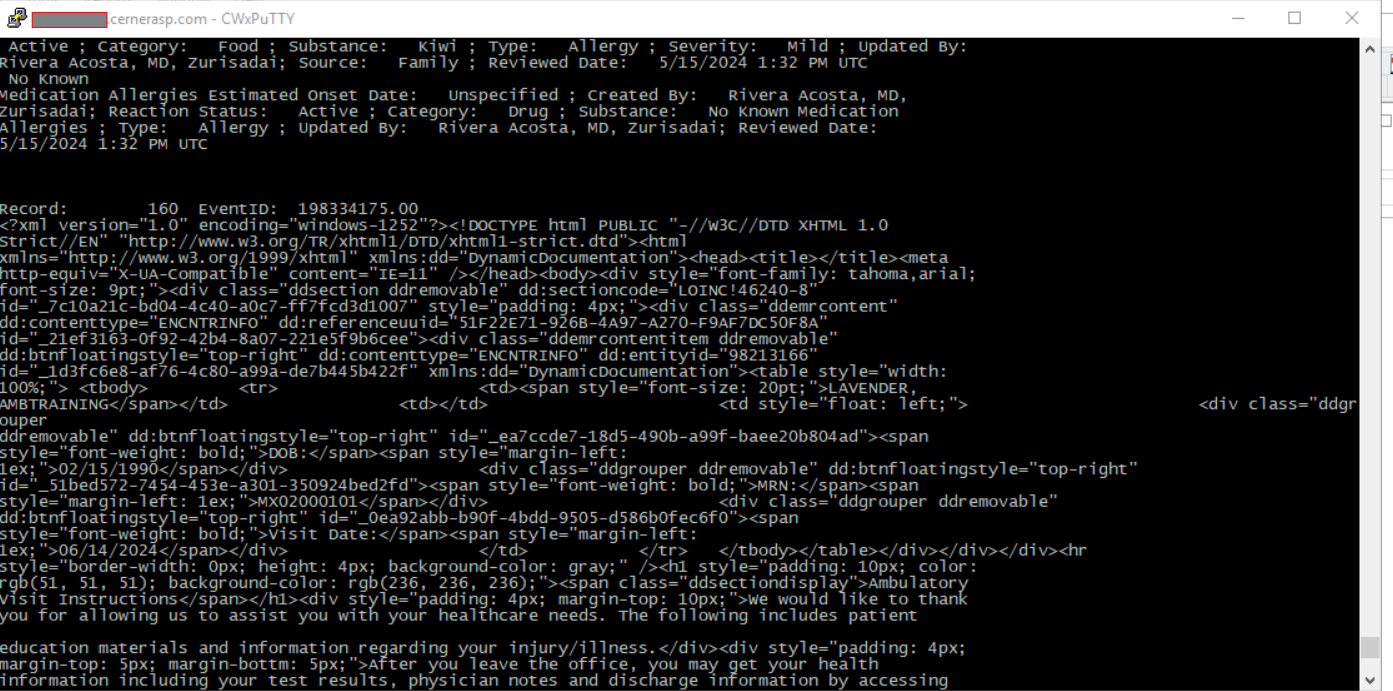
The images will look like this:
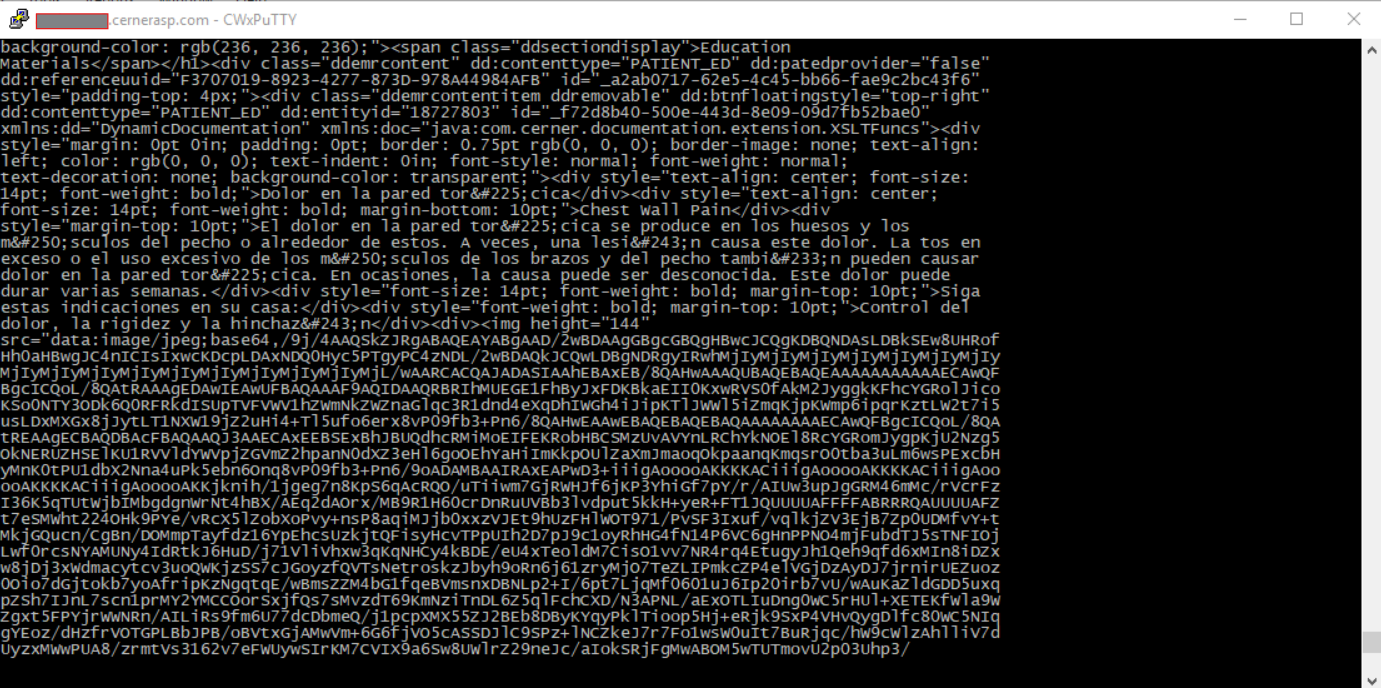
A possible way to remove the html tags would be to use external software, like for example, the https://pypi.org/project/html2text/ library for Python. This library has many configuration options, including options for managing tables and images. This would be a very simple way to convert html content into text:
import html2text
html = function_to_get_some_html()
text = html2text.html2text(html)
print(text)
You will need root privileges to install a library like html2text to the backend. We recommend extracting the blog content to a file and then move the file to a different environment to continue the data cleaning process.
VERY IMPORTANT #
If you decide to do a big unload of data onto the back-end, please remember that you should not fill-up the disk space of the directory you are using. If you fill up all available space on essential directories like CCLUSERDIR for example, then you can cause serious performance problems as Millennium servers won’t be able to log activity as they expect to.
Final notes #
The script attached is intended to obtain and uncompress data from a blog field. Once the data is uncompressed, depending on the content, you might need to use additional non-Millennium software to continue cleaning up the data.



